This year we have seen privacy become top of mind for the general public, the media and “big tech.” The business model of Google and Facebook (collect as much data as possible about users for highly targeted advertising) is under attack. Europe’s legislators were addressing some of these privacy concerns when they put into effect GDPR in 2016, the primary law regulating how companies protect EU citizens’ personal data.
But like in most cases, there are fundamental tradeoffs when it comes to making privacy the highest priority. More stringent privacy laws can make it harder for smaller platforms to run profitable businesses due to high compliance costs and hence might limit competition to the large platforms. Even more important, limiting how much user data you are allowed to collect and share with partners caps the upside of strong algorithms and the quality of (data) products.
While you might argue that nobody needs a slightly better Facebook newsfeed, everybody will probably agree that just a 1% improvement in an algorithm predicting cancer might save the lives of hundreds of thousands of people. And that’s important.
Our portfolio company Dropout Labs strongly believes that encrypted machine learning is the solution: enabling models to be trained and queried while the model, inputs, and outputs are all encrypted so no raw data is ever shared or revealed.
In the past year, the team at Dropout Labs made incredible progress with a skin cancer model, using TF Encrypted and secure multi-party computation (MPC). They were able to detect skin cancer on encrypted images and reduced the runtime from 24 hours to 36 seconds in the past few months – you can find more details about their approach in this Medium post.
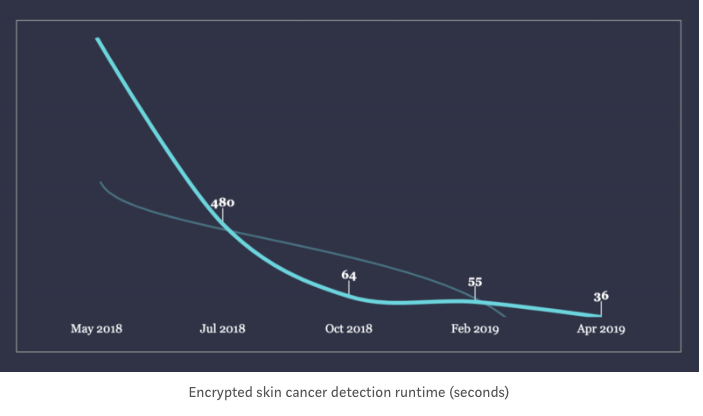
Privacy and strong data protection laws are incredibly important, but I hope that we can balance the tradeoffs with unique technology solutions like the one Dropout Labs is developing. Making it possible to bring together the right data with the right models, while respecting user data rights and privacy, can be game changing in fields like medicine. I couldn’t be more proud to see one of our portfolio companies working on such an important and hard problem.