Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
Data / AI / ML
Now more than ever, companies are collecting large amounts of data at a high frequency. This is thanks to cheap storage and a multitude of tools available to automate the process (i.e. Google Analytics, Flurry, Mixpanel, etc.). While collecting data is one thing, finding meaning or actionable insights is another task altogether. Over the past […]
Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
A month ago, we hosted the second virtual hangout with data teams across our portfolio.…
Now more than ever, companies are collecting large amounts of data at a high frequency. This is thanks to cheap storage and a multitude of tools available to automate the process (i.e. Google Analytics, Flurry, Mixpanel, etc.).
While collecting data is one thing, finding meaning or actionable insights is another task altogether. Over the past month, I have spent time with some of our portfolio companies talking about how to leverage the power of their data. At first, everyone seemed overwhelmed: “With all this data, where do we even start? We need to hire a data scientist immediately!”
If your startup is drowning in data, the good news is you can actually learn a lot about your company and product with some simple math. In particular, here are two tips that may help you make sense of this incredibly valuable asset.
1) Your data already has the answers. The challenge is asking the right question.
It’s natural to feel overwhelmed by a big question that has no apparent or obvious answer. For example, imagine asking yourself, “What day of the week is best to ramp up our ad campaigns?” The open-ended nature of this question doesn’t provide any direction toward figuring out the answer, no matter how much data you have.
Now, consider rephrasing the question above into a hypothesis: “Our best clickthrough rate is on Fridays in New York City.” As long as you have the data, it is relatively easy to prove (or disprove) this statement. And, if you find out the statement isn’t true, you can continue testing all the days and cities until you land on the right combination.
Use your intuition to come up with a hypothesis with enough granularity to focus your analysis. Don’t worry about your initial hypothesis being correct; a focused statement that’s wrong also brings you that much closer to the truth.
2) Go for the low hanging fruit.
Before applying any machine learning algorithms, it is absolutely critical that you understand your data. Otherwise, you run the risk of violating mathematical assumptions by throwing it into a black box and drawing the wrong conclusions.
The best place to start is with descriptive statistics which can offer interesting insights without any complex calculations. Here, we’re essentially referring to univariate analysis and bivariate analysis.
a) Univariate analysis
Start by exploring each variable individually. For example, you might want to look at the age of your users, the price of listings on your marketplace, or the revenue generated by each customer.
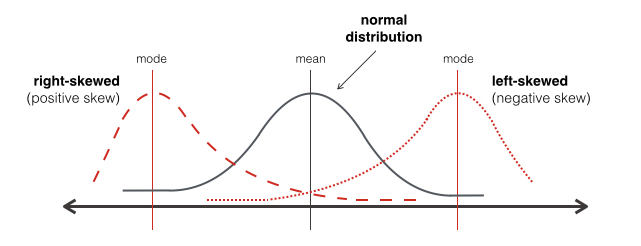
Figure 1: General forms of skewness

Figure 2: General forms of kurtosis
b) Bivariate analysis
After looking at each variable separately, consider running statistical tests on pairs of variables to find out whether there are significant correlations. Tip: if there is a strong relationship, you likely only need to include one of the two variables in your mathematical models to avoid over-representation or biasing.

Figure 3: Difference between Pearson and Spearman correlations
For those of you who have heard me carry on about my love for data, you know this post is a long time coming. I hope it serves as a prelude to a series of data-related posts to help startups navigate the world of big data. Stay tuned!
Portfolio
It’s been an eventful quarter (when has it not?), and somehow we’ve already crossed the halfway mark of 2025. We wanted to take a moment to highlight just a few of the wins, milestones, and momentum we’ve seen this past quarter. As always, there’s a whole lot happening behind the scenes that can’t be shared […]
The V1 family kicked off the new year with fresh energy and no shortage of…
At the end of Q1, we anticipated that a tech sector slowdown is ideal for…