Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
Data / AI / ML
In November, I introduced some basic statistics to help startups make sense of their data. Then last month, I described an engagement pyramid, which organizes a user’s behavior in a hierarchy. It helps you identify the highest level of user engagement so that you can allocate resources to achieve that outcome. For this blog post, […]
Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
I’m fascinated by the Open Data movement, particularly when it comes to government where the…
In November, I introduced some basic statistics to help startups make sense of their data. Then last month, I described an engagement pyramid, which organizes a user’s behavior in a hierarchy. It helps you identify the highest level of user engagement so that you can allocate resources to achieve that outcome.
For this blog post, I thought I’d combine these concepts and illustrate how they work together with a fictional example. Specifically, I’m going to focus on correlation and then introduce conditional probability as the next step to not only understanding your data, but also coming up with actionable insights.
A simple example of correlation
Suppose we are building a social app with “favouriting”/”liking” capabilities and “posting” (text, photos, etc.) capabilities. We assume that favouriting has lower user friction than posting, and want to find out the statistical relationship between these two actions. We have collected the data below:
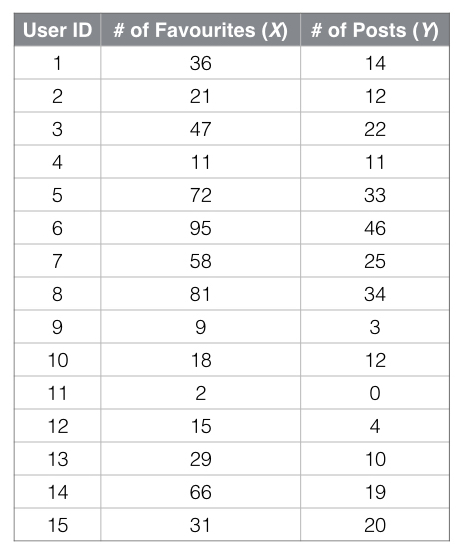
If we plot the data and apply simple linear regression, we learn that the slope m is 0.417 and the R2 value is 0.895 (see below and always remember to visualize your data: the Anscombe’s quartet will give you context as to why).
From this data, we can also calculate the Pearson correlation coefficient p, which is 0.946. In case you need to refresh your memory from November’s post, p shows the linear relationship between two sets of data (i.e. can the data be represented by a line?).
Both m and p inform us of the strength of the linear relationship between favourites and posts. However, they also provide distinct information:
Returning back to the example, there appears to be a significant linear correlation between favouriting and posting. Specifically, a correlation of 0.94 means that 89.5% (from 0.942) of variability of posting can be described by favouriting (and vice versa).
However, the shortfall of correlation is that it does not imply causation. Because we still don’t know whether favouriting lends itself to posting, we need to think about conditional probability.
Probability 101
Probability is the measure of the likeliness that an event will occur, and lies between 0 (impossibility) and 1 (certainty). Generally, probabilities can be described by the statistical number of outcomes considered favourable divided by the number of all outcomes. Some basic concepts:
The probability of an event A is written as P(A).
The opposite or complement of an event A is P(?).
e.g. If A is the event of drawing a heart from a deck of cards, then P(A) = 13/52 = 1/4. So, the probability of not selecting a heart is P(?) = 1 – 1/4 = 3/4.
If two events, A and B, are independent, then their joint probability (i.e. intersection) is P(A?B) = P(A)P(B).
e.g. If two coins are flipped at the same time, the likelihood of both being heads is P(A?B) = 1/2 * 1/2 = 1/4.
If event A or B occur in a single instance, this union denoted as P(A?B).
If these events are mutually exclusive, then the probability of either happening is P(A?B) = P(A) + P(B).
e.g. The chance of drawing a heart (A) or a spade (B) from a deck of cards is P(A?B) = 1/4 + 1/4 = 1/2.
If the events are not mutually exclusive, then P(A?B) = P(A) + P(B) – P(A?B).
e.g. The chance of drawing a heart (A) or a face card (B) or one of both is P(A?B) = 13/52 + 12/52 – 3/52 = 11/26.
Conditional probability
The probability of some event A given the occurrence of some other event B is given by P(A|B) = P(A?B)/P(B) = P(B|A)P(A)/P(B).
e.g. Suppose we have a bag with 10 blocks: 5 red and 5 blue. The probability of picking a red one in the first draw is 5/10 or 1/2 but upon taking a second block, the probability of it being either a red or blue depends on what was previously picked. If a red one was taken, then the probability of picking a red block again would be 4/9.
Understanding the concept of conditional probability is critical because it is the foundation of Bayes’ Theorem and many machine learning algorithms.
An example of conditional probability
Returning to our data set above, we can compute the likelihood that a user will post given that s/he has favourited. However, to do this, we need more granular data; that is, instead of looking at the total number of favourites and posts for each user, we must consider each favourite, post, or favourite and post, as its own event (independent of the user).
For instance, consider User 9 with a total of 9 favourites and 3 posts in (let’s say) 100 visits. His/her activity profile may look like this:

From here, we calculate:
P(Favourite) = 9/100 = 0.09
P(Post) = 3/100 = 0.03
P(Favourite ? Post) = 2/100 = 0.02
Therefore, the conditional probability of this user posting something given that s/he has favourited something is approximately 22%:
P(Post|Favourite) = P(Favourite ? Post) / P(Favourite) = 0.02/0.09 = 0.22
To find the overall probability of a user posting given that s/he has posted, you must count all activities for all visits for all users. Do not simply add the probabilities of each user.
Finally, suppose we extend this example to compute the overall conditional probability and find it to be 0.75. Because this is strong, you can focus your efforts on influencing users to favourite since you know there is a high likelihood that they will also post. You may even take advantage of the engagement pyramid and figure out the probability that someone will favourite given another lower barrier to entry activity (i.e. login). Conversely, if the probability is low, then you may want to focus on another activity.
Closing
It’s important to understand the relationship between two variables (correlation and dependence) but for more actionable results, you may want to consider looking at calculating probabilities (likelihood).
Portfolio
It’s been an eventful quarter (when has it not?), and somehow we’ve already crossed the halfway mark of 2025. We wanted to take a moment to highlight just a few of the wins, milestones, and momentum we’ve seen this past quarter. As always, there’s a whole lot happening behind the scenes that can’t be shared […]
The V1 family kicked off the new year with fresh energy and no shortage of…
At the end of Q1, we anticipated that a tech sector slowdown is ideal for…