Two months ago, I first introduced my vision to create a startup data repository. Since then, I’ve chatted with many of you who share the desire to democratize access to information on startups and bring transparency to what’s been a traditionally private ecosystem.
I’ve been blown away by the response and appreciate every like, share, tweet, retweet, email, call, and coffee meeting. I’m thrilled that I underestimated the level of interest in this topic.
I also underestimated how ambitious this goal truly is. Through all these conversations, I’ve come to realize that not everyone has the same needs and expectations for startup data. Some of you want high-level KPI data (i.e. how “fast” is a fast-growing marketplace in terms of GMV). Others are looking for baseline information on operational expenses (i.e. what is a “reasonable” cost for square foot of office space in SF).
Today, I am seeking to define the scope of this project and would love your feedback.
Vision: A centralized hub of startup data
Mission: To provide answers to those questions that founders/operators frequently ask their investors and peers, and to replace anecdotes with data-supported answers.
Strategy: To crowdsource data, KPIs and benchmarks on anything from operations to sales to hiring.
What data is available today?
If we examine the current landscape of startup data, we can categorize it into two types: 1) financial statements and financing information; and 2) general/operations information (basically anything that’s not financial). And, we find privately held and publicly available information within each of these two categories.
The following figure breaks these categories into four quadrants: privately held financial, publicly available financial, privately held general and publicly available general.
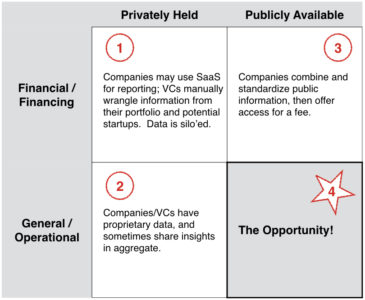
1: Privately held financial
- Founders and startups use SaaS (i.e. eShares, HockeyStick) in order to communicate their financial information to investors. In these cases, data is standardized to the SaaS’ requirements, but remains silo’ed within an organization. It’s worth noting that SaaS companies could probably do something interesting with all their data in aggregate.
- Some VCs have data and engineering teams manually wrangle non-standard financial statements and KPIs from their portfolio and pitches and create an internal repository for their own use. This data stays silo’ed (and rightfully so, given how expensive and resource-intensive this task is)
2: Privately held operational
- Some companies collect operational data as a part or side benefit of their main business. Examples are Hired, Comparably, Glassdoor and Stack Overflow for salaries and compensation. Some of these companies do share their aggregate findings, but never their raw data. This information is typically quite vertical – and even within a vertical, data isn’t standardized so there’s no way to reliably compare two data sets.
3: Publicly available financial
- Companies (like Mattermark, a V1 company) scrape the Internet, taking raw (and free) public information from social media, SEC filings and press releases and then repackaging that information into a usable database that typically requires a fee to access. Typical use cases are business development, sales, and investing.
4: Publicly available operational
- There have been some good examples of crowdsourced general or operational data. For example, First Round Capital did this with their survey (although it was not open to everyone). And many years ago, my friend Tracy Chou created a spreadsheet to gather information on diversity in tech.
The opportunity, what’s next and getting involved
After evaluating the current landscape, it’s clear that the lowest hanging fruit is in collecting general/operational data (#4). Ideally, we’d love for the repository to also shed light on financial statements and financing rounds – and perhaps in time we’ll be able to do so as we build trust and can demonstrate the value.
But for now, we’ll begin by crowdsourcing information through a series of anonymous surveys.
Are there any topics you’d like to learn more about? What questions do you have around operating costs? Are you curious about best practices in data science? What are the areas where you need more data to complement the anecdotes from founders and investors? Please leave your thoughts in the comments below.
There is so much more that we can do, so feel free to ping me with your feedback and suggestions for this project in general. And, if you’re interested in helping with this project, we’d very much appreciate it (we are a small team of two, after all!).
Until then… stay tuned for the first survey soon!