Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
Data / AI / ML
Three weeks ago, I had the pleasure of attending the Domino Data Science Pop-up, which was one of the best days of talks on data science that I have attended. You can check out recordings of the talks as well as copies of the presentations on SlideShare. I won’t dive into all the nitty-gritty discussions on math and […]
Last week, I shared some lessons learned from a Domino Data Science Pop-up that I attended a…
A few weeks ago, I attended Rev, a summit for data science leaders and practitioners organized…
Three weeks ago, I had the pleasure of attending the Domino Data Science Pop-up, which was one of the best days of talks on data science that I have attended. You can check out recordings of the talks as well as copies of the presentations on SlideShare.
I won’t dive into all the nitty-gritty discussions on math and statistics, but I do want to share some insightful discussions surrounding the definition and role of data scientists in today’s startups.
What’s a data scientist? It’s what we do, not who we are
It’s always tricky to define trendy terms – and that’s certainly true about data science. Whipple Neely, Director of Data Science at EA, gave us a better way to define a data scientist: it isn’t who we are but rather what we do.
This distinction is important for several reasons. First, it helps us better understand why and when we need data scientists (and what we can expect of them). And two, it sheds light on what we should be looking for when recruiting for data science. In the past, I have shared some insight on recruiting and hiring data scientists from my time at Insight Data Science.
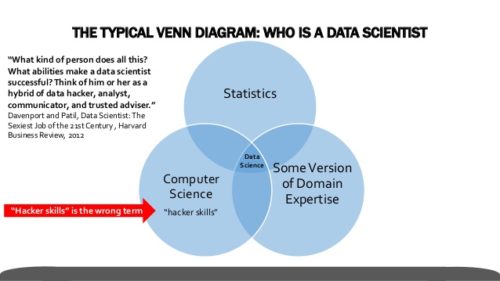
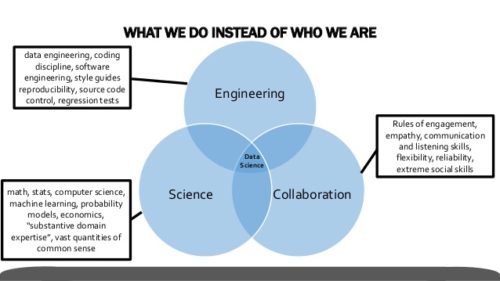
Source: Data Scientists Are Analysts are Also Software Engineers, William Whipple Neely
It turns out that a data scientist is both analyst and software engineer (and everything in between) as Neely’s presentation was aptly titled “Data Scientists Are Analysts Are Also Software Engineers.” Building models is the least important part of the job. Data science isn’t just about optimization, but also communication. Taking a black box approach to data science makes it harder to explain the insights – and the findings can come off as less believable, especially when your company’s core business isn’t machine learning.
Finding that data scientist unicorn
How do we go about finding these elusive people who are technical builders with deep mathematical knowledge, who are both product and sales-driven, and who think like a CEO with an understanding of internal and external stakeholders?
As Kimberly Shenk, Director of Data Science Solutions at Domino Data Labs, explained: “It’s hard ‘to do all and be all things’.” Therefore, she suggests the following strategy when hiring and developing the team:
You might be wondering if it is better to hire someone who is stronger technically or business-wise? It really depends on your needs and company, as you can certainly learn technical/math skills just like you can pick up business skills. Ultimately, the consensus of the crowd was that good intuition (specifically a scientific thinking process) is important. And, curiosity is the most critical attribute that can’t be taught.
On a side note, I would love to talk to anyone who has a “curriculum” or process for fostering and cultivating data science talent? Ping me and we can compare notes.
Where does data science fit in an organization?
Another great discussion focused on how to structure a data science team within your company. Is a centralized or decentralized approach better? To summarize the two:
As with anything, there’s always a tradeoff. A centralized approach creates distance between team and product, while a decentralized approach creates a risk of redundant work.
The consensus from the group is that most companies start with data science embedded with the product team, as there’s a natural fit there. Then, as the organization grows, it needs to find ways to implement a hub-and-spoke model. For more thoughts on this, you can read my friend Clare Corthell’s blog post.
Best practices in data science and engineering
Last month, I wrote about my mission to create a crowdsourced repository for startup data – stay tuned for more on this next week.
One of the key questions I want to answer is: what are the best practices when it comes to data science and engineering. Ironically, many of the decisions made on infrastructure and analysis are made through anecdotes, i.e. asking other data scientists and engineers questions like “what do you use?” and “do you build your own tools?”.
Of course, it’s not enough to consider each database, computing platform, etc. separately because everything is intertwined (as an example, just look at data at Atlassian!).
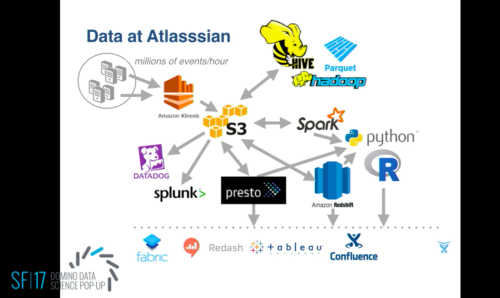
But if it is possible for us to bring some data forward on the data pipeline to complement qualitative anecdotes we get from friends, I have no doubt that that would be valuable. So if you’re interested in working on this with me, please ping me and stay tuned!
News
Happy New Year! The final quarter of 2025 brought meaningful momentum across the V1 portfolio, with founders closing Q4 strong and building toward an even bigger 2026. We’re excited to carry that progress into the months ahead. Before we fully shift our focus to what’s next, here’s a look back at a few highlights and […]
Yet another year has flown by. This past quarter was a busy one, which should…
The V1 family kicked off the new year with fresh energy and no shortage of…